
你所不知道的JavaScript①--数据类型及周边
关键词
类型、栈和堆、检测方式、数据类型转换
类型
首先js的类型有基本数据类型和引用类型
前者有七种 后者是一种
根据以前的USONB理论 大致是Undefined,String,Symbol,Object,Null,Number,BigInt,Boolean
基本数据类型的作用?
基础类型存储在栈内存,被引用或拷贝时,会创建一个完全相等的变量;占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储。
object为什么是引用类型?
而引用类型 在创建对象的时候会在堆内存中开辟一个空间 用来存放对象的属性 在为对象添加属性的时候,是将属性放在堆内存中开辟的空间里。
在栈内存中保存显示 对象名+一个地址 类似于指针 执行堆内存中对象开辟的空间
引用类型存储在堆内存,存储的是地址,多个引用指向同一个地址,这里会涉及一个“共享”的概念;占据空间大、大小不固定。引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
引申出栈和堆的概念!
BigInt
js的精度只有2的53次方,所以当数据大于这个数的时候会出现解析不准确(最后一位被四舍五入),这个时候就需要这个库来帮忙解决。
- 业务场景
1 | const request = axios.create({ |
- 创建bigint,只需要在数字结尾加个n即可。或者使用
BigInt()构造函数,但此时要传入字符串
1 | console.log(99151651515165151n)//99151651515165151n |
- 注意控制台中输出bigint的数据 是绿色的。
- 不能用三个等于判断
BigInt和常规数字 因为它们的类型不同
1 | console.log(10n===10)//false; |
- 不支持一元加号(+)
1 | 10n + 20n; // → 30n |
栈和堆
在js的执行过程中,主要有三种类型的内存空间,一是代码空间,二是栈空间,三是堆空间。代码空间顾名思义就是存储代码用的,栈空间是用来保存变量和变量值的,堆空间是保存地址的。
对于栈空间来说,原始类型存储的是变量的值,而引用类型存储的是在堆空间中的地址,所以当js需要访问数据的时候,是通过栈中的引用地址来访问的,相当于多了一道转手程序
闭包是怎么存储
js引擎对于闭包的处理,是当遇到一个闭包的时候,在堆空间中创建一个closure(fn)对象,用来保存闭包中的变量,所以闭包中的变量是存储在堆空间中的。这就是为什么闭包可以常驻在内存的原因。
js为什么需要栈和堆
首先知道栈是让变量循环利用,通常也是设置一些小数据来放入栈中,而我们知道引用类型数据obj一般占用的空间都比较大。所以js引擎需要栈和堆来维持内存的平衡。
- 题目1第一个是lee显而易见,第二个console是son 第三个也是。这是因为a是对象 是引用类型 在赋值给b的时候 实际上是给了a在堆中的地址 所以b访问的是堆空间中a的变量 那么修改了b 自然a也会发生变动,这里就引出了堆空间共享的概念
1
2
3
4
5
6
7
8
9let a = {
name: 'lee',
age: 18
}
let b = a;
console.log(a.name); //第一个console
b.name = 'son';
console.log(a.name); //第二个console
console.log(b.name); //第三个console - 题目2第一个输出30 第二个输出24
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15let a = {
name: 'Julia',
age: 20
}
function change(o) {
o.age = 24;
o = {
name: 'Kath',
age: 30
}
return o;
}
let b = change(a); // 注意这里没有new,后面new相关会有专门文章讲解
console.log(b.age); // 第一个console
console.log(a.age); // 第二个console
原因是function里面传入的是a在堆中的地址,那么自然a的age就会变成24 但是到了return这一步 它会把传入的内存地址修改 导致o变成另外一个内存地址 将o的数据存放在该内存中, 所以b就是kath和30
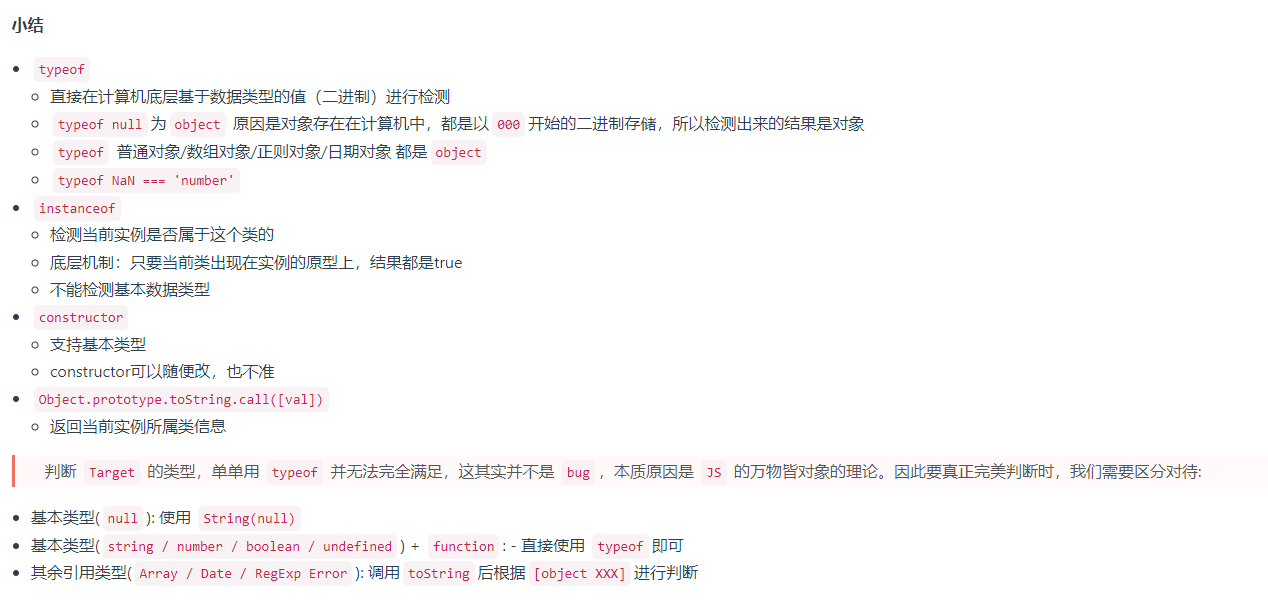
检测方式
数据类型检测有很多种,常用的是typeof instanceof constructor Object.prototype.toString.call([])
typeof
该方法是基于计算机底层的数据类型的二进制进行判断。 用于判断除了array null之外的类型,即可以判断除了null之外的基础数据类型和除了array之外的应用数据类型
下面看一下它对于所有类型的处理 注意它可以处理function
1 | console.log(typeof 2); // number |
- 为什么null会被
typeof识别成object?
这个是一个历史遗留问题 js底层是二进制存储的 前三位代表的是数据的存储类型 对于object来说则是000 而刚好null也是全0 正好代表object类型的数据格式 所以null才会输出object
instanceof
由于上面的方法不能精确判断数组和null的原因 所以产生了新的方法instanceof
康康它对于所有类型的处理
1 | console.log(2 instanceof Number); // false |
和由此可见 instanceof方法能准确的判断引用数据类型 但是不能判断基础数据类型
因为它的原理是和原型链相关的 ,相当于判断是不是这个类的实例,所以对于undefined和null来说,这两者是没有原型的 所以无法判断。
引申一下 null是所有原型的终点 undefined是表示没有这个值 缺少这个值
constructor
1.对象原型proto和构造函数原型对象prototype里面都有一个constructor属性
2.constructor 称为构造函数 因为它的作用是用于new的实例对象指回构造函数本身
3.constructor 主要用于记录该对象是用于那个构造函数 它可以让原型对象prototype重新指向原来构造他的构造函数
注:如果我们修改了原来的原型对象,给原型对象赋值的是一个对象,则必须手动的利用constructor指回原来的构造函数
记得括号1
2
3
4
5
6console.log((2).constructor === Number); // true
console.log((true).constructor === Boolean); // true
console.log(('str').constructor === String); // true
console.log(([]).constructor === Array); // true
console.log((function() {}).constructor === Function); // true
console.log(({}).constructor === Object); // true
通俗解释就是构造函数指向原型,但如果改变了原型,指向就变得不正确了。1
2
3
4
5
6
7
8function Fn(){};
Fn.prototype=new Array();
var f=new Fn();
console.log(f.constructor===Fn); // false
console.log(f.constructor===Array); // true
当然针对这种弊端也有解决方法:把constructor指向改变回去(废话)1
2
3
4
5
6
7
8
9
10
11function Fn(){};
Fn.prototype=new Array();
Fn.prototype.constructor = Fn;
var f=new Fn();
console.log(f.constructor===Fn); // false
console.log(f.constructor===Array); // true
Object.prototype.toString.call()
使用Object上面的toString方法 会返回一个格式为[object Xxx]的字符串,通过call重新调用就可以精确判断对象类型
1 | Object.prototype.toString({}) // "[object Object]" |
由于代码过长 推荐封装一下Object.prototype.toString
实现一个全局通用的判断方法
1 | function getType(obj){ |
为什么需要prototype?
直接使用的话 他直接找到当前对象的toString方法,返回的是当前对象的字符串形式,不同的对象持有的toString方法不一样,按照原型链的思路会优先使用重写的方法,所以无法判断,除非删掉他。或者使用Object.prototype上的toString方法。1
2
3
4
5
6var arr=[1,2,3];
console.log(Array.prototype.hasOwnProperty("toString"));//true
console.log(arr.toString());//1,2,3
delete Array.prototype.toString;//delete操作符可以删除实例属性
console.log(Array.prototype.hasOwnProperty("toString"));//false
console.log(arr.toString());//"[object Array]"
为什么需要call?
数据类型转换
在js中 类型转换有三种情况 分别是
- 转换为布尔值
- 转换为数字
- 转化为字符串
一图流: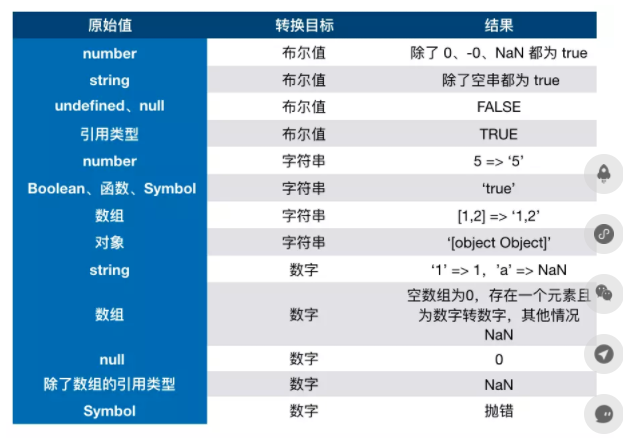
转Boolean
在条件判断的时候,除了undefined,null,false,NaN,`,0,-0`,其他值都会转成true 包括对象
1 | Boolean(0) //false |
对象转原始类型
对象转原始类型的时候,会调用内置的[[ToPrimitive]]函数,对于该函数来说,算法逻辑一般如下
- 如果已经是原始类型了,那么就不需要转换了
- 调用
x.valueOf()如果转换为基础类型,那么就返回转换的值。 - 调用
toString()如果转换为基础类型,就返还转换的值。 - 如果都没有返回原始类型,就会报错。
当然你也可以重写Symbol.toPrimitive该方法在转原始类型的时候调用优先级最高
1 | let a = { |
四则运算符
他有以下几个特点:
- 运算中如果其中一方为字符串,就会把另外一方也转换成字符串。
- 如果其中一方不是字符串或者数字,那么会将他转换成数字或者字符串。
1 | 1+'1' //11 |
- 第一行 特点一
- 第二行 特点二
- 第三行 特点二
另外对于加法还需要注意表达式a ++ b
1 | 'a' + + 'b' // "aNaN" |
- 因为
+ 'b'的结果是NaN所以…且在部分代码中有尝试使用+某个值的形式来快速获取number类型 - 那么对于除了加法的运算符来说,只要其中一方是数字,那么另外一方就会被转为数字。
1 | 4*'3'//12 |
比较运算符
- 如果是对象,就通过
toPrimitive转换对象。 - 如果是字符串,就通过
unicode字符索引来比较。
1 | let a = { |
在以上代码中,a是对象,所以通过valueOf转化为原始类型再比较
强制类型转换
强制类型转换的方式包括Number(),parseInt(),parseFloat(),toString(),String(),Boolean()这几种方法都比较类似。
Number的强制转换规则- 如果是布尔值
true是1false是0 - 如果是数字,返回自身
- 如果是
null返回 0 - 如果是
undefined返回NaN - 如果是字符串 遵循以下规则:如果字符串中只包含数字 或者是
0x开头的十六进制数字字符串,允许包含正负号。则将其转换为十进制;如果字符串中包含有效的浮点格式,将其转换为浮点数值;如果是空字符串,将其转换为0;如果不是以上格式的字符串,均返回NaN - 如果是
Symbol抛出错误 - 如果是对象,并且部署了
[Symbol.toPrimitive],那么调用此方法,否则调用valueOf方法,然后根据前面的规则返回转换的值。如果转换的结果是NaN,那么调用对象的toString()方法,再次按照前面的规则返回对应的值。
1 | Number(true); // 1 |
Object的转换规则
对象转换的规则,会先调用内置的[Symbol.ToPrimitive]函数,其规则逻辑如下:
- 如果部署了该方法,优先调用再返回。
- 调用
valueOf如果转换为基础类型 则返回 - 调用
toStirng如果转换为基础类型 则返回 - 如果都没有 则报错
1 | var obj = { |
==的隐式转换规则
- 如果类型相同,无需进行类型转换。
- 如果其中一个是
null或者undefined那么另外一个操作符必须是null或者undefined才会返true 否则都是false - 如果其中一个是
Symbol类型 那么返回true - 两个操作值如果是
string和number类型,则转字符串为number - 如果一个是
boolean则转number - 如果一个操作值为
object且另一方为number string or Symbol就会把object转化为原始类型再进行判断
1 | null == undefined // true 规则2 |
+的隐式转换规则
加号操作符,,不仅可以用作数字相加,还可以用作字符串拼接,仅当加号两边都是数字的到时候,进行的是加法运算,如果两边都是字符串,直接拼接,无需进行隐式转换。
- 如果其中有一个是字符串,另外一个是
undefined,null或者布尔型,则调用toStirng方法进行字符串拼接;如果是纯对象,数组,正则等。则默认调用对象的转换方法会存在优先级,然后再进行拼接。 - 如果其中有一个是数字,另外一个是
undefined,null或者布尔型,则会将其转换成数字进行加法运算,对象同上一条规则。 - 如果其中一个是字符串,另一个是数字,则拼接。
1 | 1 + 2 // 3 常规情况 |
null和undefined的区别
- 首先
undefined和null都是基本数据类型,这两个基本数据类型分别都只有一个值。就是undefined和null undefined代表的含义是未定义,null代表的含义是空对象,其实不是真的对象。一般变量声明了还没有定义的时候是undefined,null主要用于赋值给一些可能返回对象的变量,作为初始化。
其实null不是对象,虽然typeof null会输出object,但是这个只是js的历史遗留问题,000开头的是对象,null也是正好全0 所以判了是object 但实际不是
undefined在js中不是一个保留字,这意味着我们可以用undefined来作为一个变量名,but这样的做法非常的危险,他会影响我们对undefined值的判断。但我们可以通过一些方法获取安全的undefined值,比如说void 0
为什么0.1+0.2!==0.3
并不是所有的小数都能用二进制数来表示,比如0.1转换成小数的时候就是一个无限循环的二进制数,又因为计算机的资源是有限的,所以采用了近似值来表示该二进制数。
js采用的是IEEE 754的64位双精度标准,浮点数使用的是64位固定长度表示的,其中的一位表示符号位,11位用来表示指数位,剩下的52位是尾数位
而0.1转为二进制是一个无限循环数0.0001100110011001100…(1100循环)
以至于计算还没开始,一个很小的舍入错误就已经产生了。这也就是 0.1 + 0.2 不等于0.3 的原因。
解决方法:
toFixed方法:toFixed() 进行转换之后是string类型的,需要再进行强制转换
1
parseFloat((0.1 + 0.2).toFixed(10)) === 0.3 // true
可以通过引入 math.js 或者 bigNumber.js 进行解决
1
2new BigNumber(0.2).plus(0.1).toString() // '0.3'
new BigNumber(19.9).plus(0.01).toNumber() // 19.91分别先乘10的倍数,然后再除10
1
console.log(( 0.1*10 + 0.2*10 ) / 10 ) //0.3
为什么0.2+0.3=0.5呢?
1 |
|
0.2 和0.3分别转换为二进制进行计算:在内存中,它们的尾数位都是等于52位的,而他们相加必定大于52位,而他们相加又恰巧前52位尾数都是0,截取后恰好是0.1000000000000000000000000000000000000000000000000000也就是0.5
那既然0.1不是0.1了,为什么在console.log(0.1)的时候还是0.1呢?
在console.log的时候会二进制转换为十进制,十进制再会转为字符串的形式,在转换的过程中发生了取近似值,所以打印出来的是一个近似值的字符串
isNaN和Number.isNaN的区别
前者是ES6之前的全局方法,判断的方式是先把传进来的内容使用Number进行转换,然后再判断是否为NaN,后者更方便一点,首先判断传进来的内容是否为数值类型,非数值直接返回NaN,










