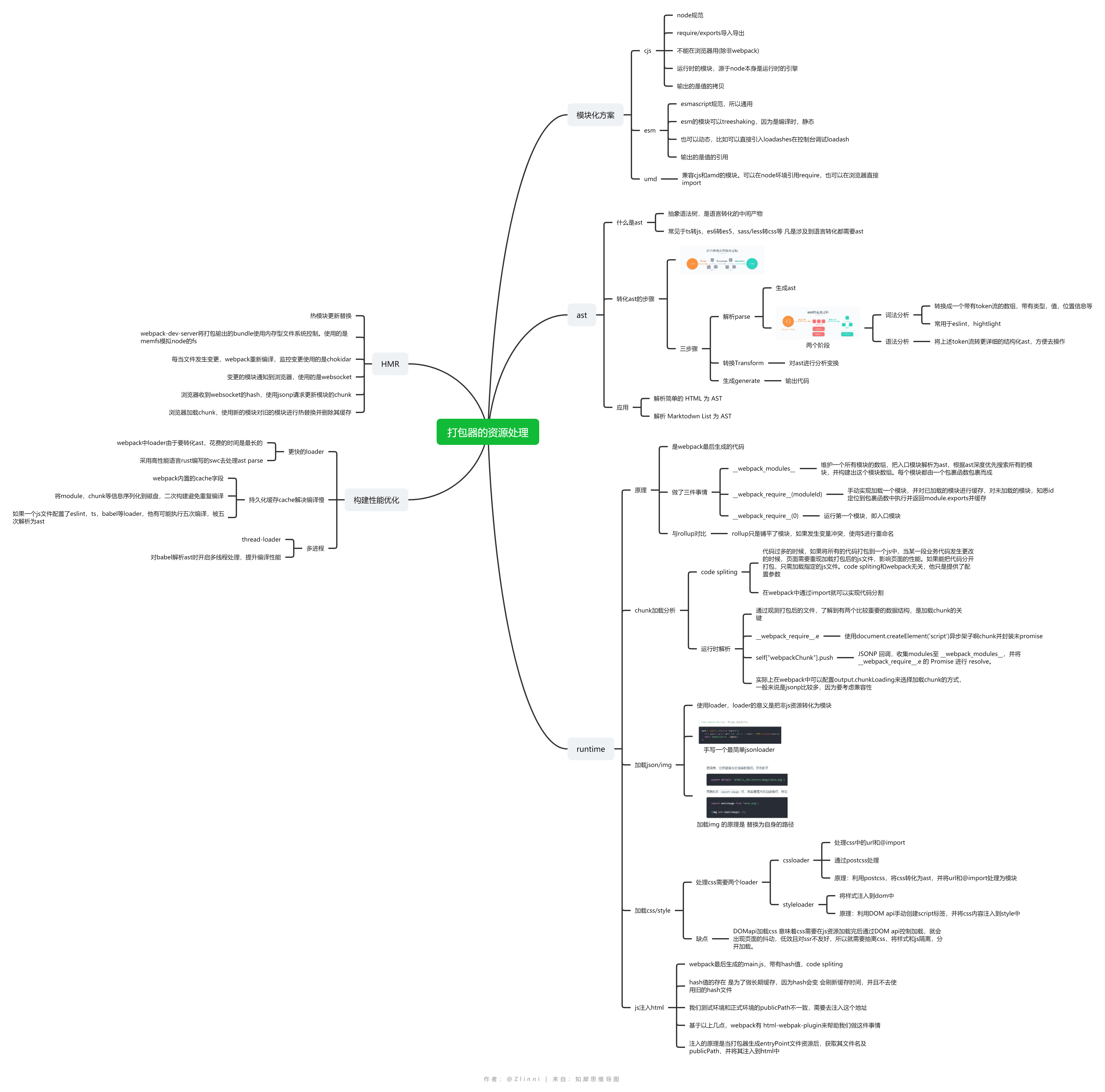
前端工程化①打包器的资源处理
前言
在前端工程化这块,打包肯定是大家初次入门的时候会接触到的玩意,最常见的一个例子就是第三方资源 CDN 外部引入。在网上各路教程中都说明他是减少了项目体积,实则不然,下面详细讲述前端打包的方案
模块化方案
对于模块化,cjs,es,umd 模块你知道吗?
cjs
首先是 cjs,全称 Commonjs,是 node 中的模块规范,通过 require 及 export 进行导入导出,进一步延申的化,module.export属于 commonjs2.
因为他属于 node 的模块,也就是意味着他只能在 node 环境中,也就是不能直接用在浏览器之上。如果你的前端项目需要用到以 cjs 规范写的模块,那么就会出问题(比如 cdn 加载)。
1 | // sum.js |
解决方法是 webpack 的 enhanced-resolve,webpack 是通过引入这个库来解析模块的,他相当于增强版的require.resolve。他会将 require 或者 import 语句中的资源,解析为引入文件的绝对路径,然后通过文件读取加载资源。具体参见这篇文章【webpack 系列】3. webpack 是如何解析模块的
关键字:cjs,node,require 和 export
esm
全称es module。是 tc39 对于 ESMAScript 的模块化规范,因为他是规范,所以能用在 node 和浏览器环境下,使用import/export进行模块的导入导出
1 | // sum.js |
esm 为静态导入,正因为如此,可以在编译的时期进行 tree shaking,减小 js 体积。(判断一个模块是否支持 tree shaking 就要看他发包内容有没有 es,而不是看源码是不是 esm 写的)
如果需要动态导入,tc39 为动态加载模块定义了 API: import(module) 。可将以下代码粘贴到控制台执行
1 | const ms = await import("https://cdn.skypack.dev/ms@latest"); |
esm 是未来的趋势,目前一些 cdn 厂商和前端构建工具都致力于 cjs 模块像 esm 的转化,比如 skypack、 snowpack、vite 等。
目前浏览器和 node 均支持 esm
cjs 和 esm 的区别
- cjs 模块输出的是一个值的拷贝,esm 输出的是值的引用
- cjs 是运行时加载,esm 是编译时加载。
怎么理解这句话呢,实际上可以直接拿 cdn 的 esm 模块来使用,array-uniq,就会发现我们并没有使用到他,但是他已经加载出来了。相应的 cjs 模块就不行。源于 nodejs 是 js 的一个解析引擎,是运行时的。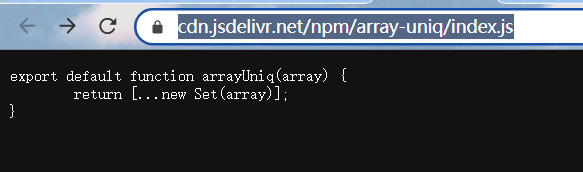
umd
umd 是一种兼容 cjs 和 amd 的模块,既可以在 node/webpack 环境中被 require 使用,也可以在浏览器中直接用 cdn 以script.src引入
1 | (function (root, factory) { |
可以看出 umd 的本质就是一个 IIFE。
这三种模块方案大致如此,部分 npm package 也会被同时打包出 commonjs/esm/umd 三种模块,以供不同的需求的业务使用。比如 antd
AST 抽象语法树
AST 全称 Abstract Syntax Tree,抽象语法树,涉及到工程化的诸多环节的应用,比如:
- 如何将 ts 转换为 js
- 如何将 sass/less 转化为 css
- 如何将 es6 转化为 es5(babel)
- 如何将 js 代码格式化 prettier/eslint
- 如何识别 jsx
- graphQL,MDX,Vue SFC 等等
这种语言转换的过程实际就是对其 AST,核心步骤是
- code -> ast(parse)
- ast -> ast(transform)
- ast -> code(generate)
1 | // Code |
我们在 vue 的环节中也讲到了如何解析模板语法为 ast,就是生成类似的对象。对于不同语言有不同的解析器,js 的解析器和 css 的解析器就完全不一样。相同的语言也有不同的解析器,比如 babel 和 espree
AST 的生成
这一步称之为解析 parse,这个步骤有两个阶段,一是词法分析,二是语法分析。
词法分析是将代码转化为 token 数组,我们常见的 mdeditor 和 eslint,hightlight,模板语法等就是利用了这个步骤去判断
1 | // Code |
语法分析是将 token 流转化为结构化的 ast,方便操作。
1 | { |
实践
可通过自己写一个解析器,将语言 DSL 解析为 AST 进行练手,以下两个示例是不错的选择
- 解析简单的 HTML 为 AST
- 解析 Marktodwn List 为 AST
或可参考一个最简编译器的实现 the super tiny compiler
原理与运行时分析
webpack runtime
webpack 的 runtime,也就是 webpack 最后生成的代码,做了以下三件事:
_webpack_modules_:维护一个所有模块的数组。将入口模块解析为 ast,根据 ast 深度优先搜索出所有的模块,并构建出这个模块数组。每个模块都由一个包裹函数(module, module.exports, __webpack_require__)对模块进行包裹而成。__webpack_require__(moduleId)手动实现加载一个模块。对已经加载过的模块进行缓存,对未加载的模块,执行 id 定位到__webpack_modules__中的包裹函数,执行并返回 module.exports 并缓存__webpack_require__(0): 运行第一个模块,即运行入口模块
另外,当涉及到多个 chunk 的打包方式中,比如 code spliting,webpack 会有 jsonp 加载 chunk 的运行时代码
以下是 webpack runtime 的最简代码,配置示例可见 node-examples
1 | /******/ var __webpack_modules__ = [ |
对 webpack runtime 做进一步的精简,代码如下
1 | const __webpack_modules__ = [()=>{}]; |
rollup
在 rollup 中,并不会将所有模块置于 modules 中使用 Module Wrapper 进行维护,他仅仅将所有模块铺平展开。
举例
1 | // index.js |
对于他的这种方案要是遇到变量冲突如何解决,如下:直接重新命名
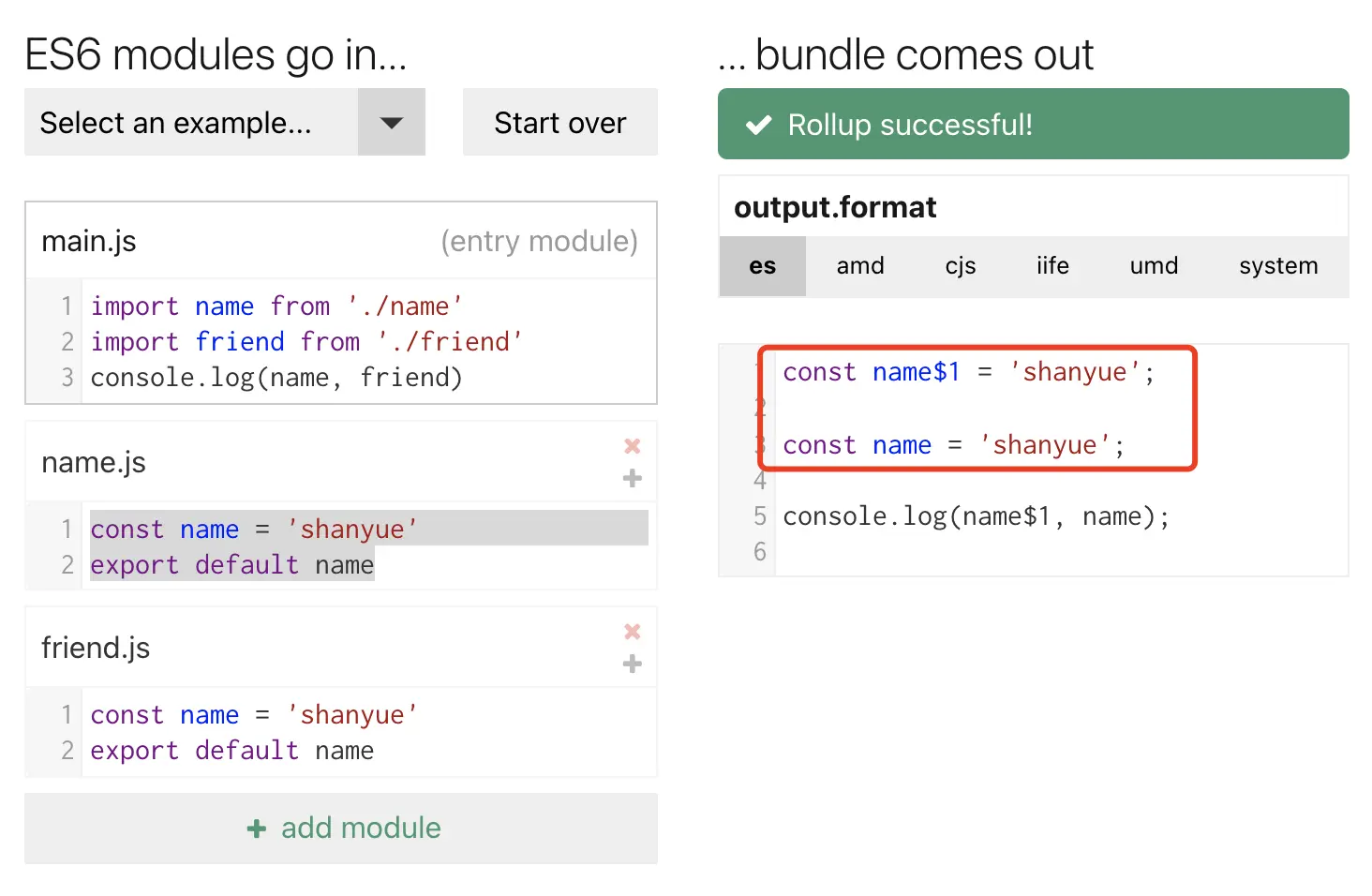
运行时 chunk 加载分析
问:webpack 的 code spliting 是如何动态加载 chunk 的?
一个 webpack 运行时,包括最重要的两个数据结构:
__webpack_modules__维护一个所有模块的数组。将入口模块解析为 ast,根据 ast 深度优先搜索所有的模块,并构建出这个模块数组。每个模块都由一个包裹函数(module, module.exports, __webpack_require__)对模块进行包裹而成。__webpack_require__(moduleId)手动实现加载一个模块。对已经加载过的模块进行缓存,对未加载的模块,根据 id 定位到__webpack_modules__中的包裹函数,执行并返回module.exports并缓存。
code spliting
在 webpack 中通过 import 可以实现 code spliting。假设有以下文件:
1 | // index.js |
使用下面的 webpack 配置进行打包
1 | { |
运行时解析
观测打包后的文件dist/deterministic/main.xxxxxx.js,可以发现:使用import()加载数据时,以上代码将被编译为以下代码
1 | __webpack_require__ |
此时 644 为 chunkId,观测chunk.sum.xxx.js文件,以下为 sum 函数所构建的 chunk
1 | ; |
以下两个数据结构是加载 chunk 的关键:
__webpack_require__.e:加载 chunk。该函数使用document.createElement('script')异步加载 chunk 并封装为 promise。self["webpackChunk"].push:JSONP callback,收集 modules 至__webpack_modules__并将__webpack_require__.e的 promise 进行 resolve
实际上在 webpack 中可以配置output.chunkLoading来选择加载 chunk 的方式,比如选择通过import()的方式来加载。(由于在生产环境中要考虑 import 的兼容性,目前 JSONP 的方案比较多)
1 | { |
打包器(webpack/rollup)如何加载 json,image 等非 js 资源
我们知道在 webpack 中一切都是模块,所以加载 json 等非 js 资源的时候,就需要模块加载器,也就是俗称的 loader。将他们转化为模块。
加载 json
以 json 为例子
1 | // user.json 中内容 |
在现代前端中,我们把他视为 module 时,使用 import 引入资源。
1 | import user from "./user.json"; |
而我们的打包器,如 webpack 与 rollup,将通过以下的方式来加载 json 资源
这样将被视为普通的 js
1 | // 实际上会被编译为以下内容 |
在 webpack 中通过 loader 处理此类资源,示例如下:
1 | module.exports = function (source) { |
加载图片
那图片是如何处理的呢?
更简单,他将替换成自身的路径。示例如下:
1 | export default `$PUBLIC_URL/assets/image/main.png`; |
而我们在import image的时候,其实是图片自身的路径,将他置于src属性即可。
1 | import mainImage from 'main.jpg'; |
加载 css
在 webpack 中处理 css 比较费劲。需要借用两个 loader 来做这件事。
1 | module.exports = { |
css-loader处理 css 中url与@import,并将其视为模块引入,此处是通过 postcss 来解析处理。postcss 对于工程化中 css 的处理可见一斑。style-loader将样式注入到 DOM 中。
1 | @import url(./basic.css); |
原理
cssloader 的原理就是 postcss,借用postcss-value-parser解析 css 为 ast。并将 css 中的url()与@import解析为模块。
styleloader 将 css 注入到 dom,原理为使用 DOM API 手动创建 style 标签,并将 css 内容注入到 style 中。
源码实现中借用了许多运行时代码。而最简单的实现仅需几行代码
1 | module.exports = function(source){ |
使用 DOM API 加载 CSS 资源,由于 CSS 需要在 JS 资源加载完后通过 DOM API 进行控制加载,容易出现页面抖动,在线上低效且性能低下。且对于 SSR 极其不友好。
由于性能需要,在线上通常单独加载 css,这就要求打包器能够将 css 打包,此时需要借助于mini-css-extract-plugin将 css 单独抽离出来。
注入 js 到 html
如果最终打包的 mainjs 既没有做 code spliting,也没有做 hash 化路径。大可以通过在index.html中手动控制 js 资源。
1 | <body> |
不过往往事与愿违:
- mainjs 即我们最后生成的文件带有 hash 值。
- 由于长期缓存的需要,入口文件不仅只有一个,还包括第三方模块打包而成的 vendorjs,同样带有 hash
- 脚本地址同时需要注入 publicPath,而在生产环境与测试环境的 publicPath 并不一致。
因此需要一个插件做这件事情,在 webpack 中叫html-webpack-plugin在 rollup 的世界里叫@rollup/plugin-html
而注入的原理为当打包器已生成 entryPoint 文件资源后,获得其文件名以及 publicPath,并将其注入到 html 中
以 html-webpack-plugin 为例,它在 compilation 处理资源的 processAssets 获得其打包生成的资源。伪代码如下,可在 mini-node:html-webpack-plugin (opens new window)获得源码并运行示例。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52class HtmlWebpackPlugin {
constructor(options) {
this.options = options || {};
}
apply(compiler) {
const webpack = compiler.webpack;
compiler.hooks.thisCompilation.tap("HtmlWebpackPlugin", (compilation) => {
// compilation 是 webpack 中最重要的对象,文档见 [compilation-object](https://webpack.js.org/api/compilation-object/#compilation-object-methods)
compilation.hooks.processAssets.tapAsync(
{
name: "HtmlWebpackPlugin",
// processAssets 处理资源的时机,此阶段为资源已优化后,更多阶段见文档
// https://webpack.js.org/api/compilation-hooks/#list-of-asset-processing-stages
stage: webpack.Compilation.PROCESS_ASSETS_STAGE_OPTIMIZE_INLINE,
},
(compilationAssets, callback) => {
// compilationAssets 将得到所有生成的资源,如各个 chunk.js、各个 image、css
// 获取 webpac.output.publicPath 选项,(PS: publicPath 选项有可能是通过函数设置)
const publicPath = getPublicPath(compilation);
// 本示例仅仅考虑单个 entryPoint 的情况
// compilation.entrypoints 可获取入口文件信息
const entryNames = Array.from(compilation.entrypoints.keys());
// entryPoint.getFiles() 将获取到该入口的所有资源,并能够保证加载顺序!!!如 runtime-chunk -> main-chunk
const assets = entryNames
.map((entryName) =>
compilation.entrypoints.get(entryName).getFiles()
)
.flat();
const scripts = assets.map((src) => publicPath + src);
const content = html({
title: this.options.title || "Demo",
scripts,
});
// emitAsset 用以生成资源文件,也是最重要的一步
compilation.emitAsset(
"index.html",
new webpack.sources.RawSource(content)
);
callback();
}
);
});
}
}
HMR
全称Hot Module Replacement,热模块替换,无需刷新在内存环境中即可替换掉旧模块。与live Reload相对应
在webpack的运行时中,__webpack_modules__用于维护所有模块。
而热模块替换的原理,即是通过chunk的方式加载最新的modules,找到_webpack_modules_里面对应的模块逐一替换。并删除其上下缓存
其精简数据结构如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// webpack 运行时代码
const __webpack_modules = [
(module, exports, __webpack_require__) => {
__webpack_require__(0);
},
() => {
console.log("这是一号模块");
},
];
// HMR Chunk 代码
// JSONP 异步加载的所需要更新的 modules,并在 __webpack_modules__ 中进行替换
self["webpackHotUpdate"](0, {
1: () => {
console.log("这是最新的一号模块");
},
});
以下为更具体更完整的流程,每一步都涉及很多,有兴趣的可以阅读webpack-dev-server以及开发环境webpack运行时的源码
- webpack-dev-server将打包输出bundle使用内存型文件系统控制,而非真实的文件系统。此时使用的是memfs模拟node的fs API
- 每当文件发生变更的时候,webpack会重新编译,webpack-dev-server将会监控到此时文件变更事件。并找到对应的module。此时使用的是chokidar的文件监控模块
- webpack-dev-server将会把变更模块通知到浏览器端,此时使用websocket与浏览器进行交流。此时使用的是ws
- 浏览器根据websocket接收到hash,并通过hash以jsonp的方式请求更新模块的chunk
- 浏览器加载chunk,并使用新的模块对就模块进行热替换。并删除其上下缓存
构建性能优化
首先我们要知道怎么评估性能:使用speed-measure-webpack-plugin可以评估每个loader/plugin的执行耗时。
更快的loader:swc
在webpack中耗时最久的是负责ast转换的loader。
当loader进行编译的时候,ast操作均为cpu密集型任务,使用js性能低下,此时可以采用高性能语言rust编写的swc
比如js转化由babel转化为更快的swc
1 | module: { |
持久化缓存cache
webpack内置了关于缓存的插件,可以通过cache字段开启。
他将module,chunk等信息序列化到磁盘中,二次构建避免重复编译计算,编译速度得到很大的提升。
1 | { |
如对一个js文件配置了eslint,ts,babel等loader。可能执行五次编译。被五次解析为ast。
- acorn:用于依赖分析,解析为acorn的ast
- eslint-parser: 用以lint,解析为espree的ast
- ts:用以ts…
- babel: 转化es6+
- terser:压缩混淆。解析为acorn的ast
当开启了持久化缓存,最耗时的ast解析将能够从磁盘的缓存中获取,再次编译时无需进行解析ast
得益于持久化缓存。二次编译甚至可得到与unbundle的vite相近的开发体验。
多线程 thread-loader
thread-loader为官方推荐的开启多线程的loader,可以对babel解析ast时开启多线程处理,提升编译的性能。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18module.exports = {
module: {
rules: [
{
test: /\.js$/,
use: [
{
loader: "thread-loader",
options: {
workers: 8,
},
},
"babel-loader",
],
},
],
},
};
在webpack4中使用的是happypack plugin。but他已经很久不维护了。
总结