从零开始的mini-vue⑧--parse篇
前言
mini-Vue 是精简版本的 Vue3,包含了 vue3 源码中的核心内容,附加上 demo 的具体实现。
本篇是模板编译 Intro 篇,是关于 Vue3 中模板编译的简单介绍。
编译的目的
之前我们编译都是以手写渲染函数的形式进行的,因此进行模板编译的目的就是将模板代码编译成渲染函数
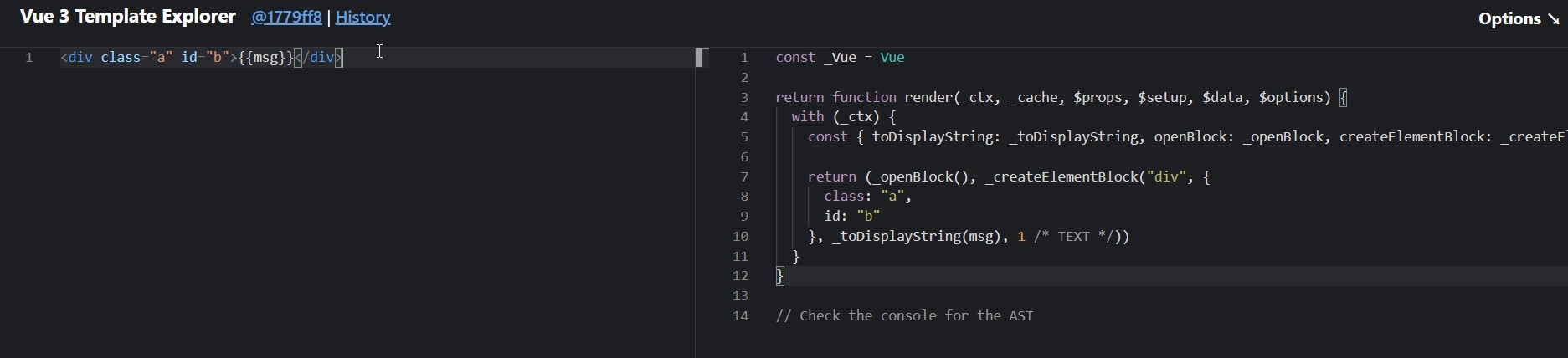
这里的_createElementBlock就相当于 h 函数,_toDisplayString就是为了转换插值符号 msg 的结果
这里值得一提的是 vue 能支持 jsx 的原理,因为 jsx 的最终产物也是一段渲染函数。
编译的步骤

parse
原始的模板代码就是一段字符串,通过解析 parse 转为原始的 AST 抽象语法树
transform
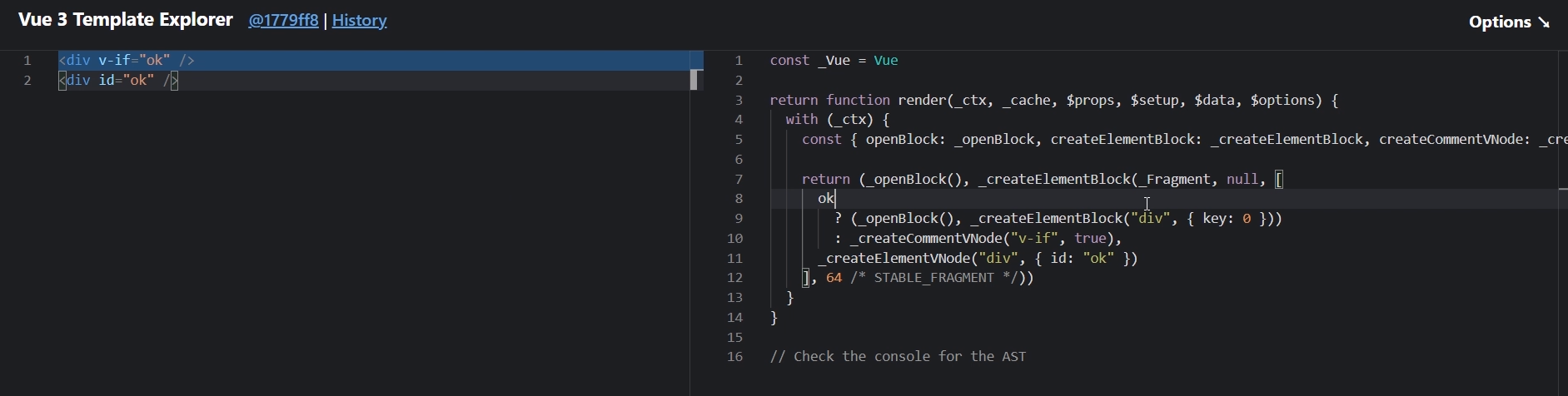
AST 经过 transform 生成一个 codegenNode。codegenNode 是 AST 到生成渲染函数代码的中间步骤,它由原始的 AST 语义而得来。比如对于原始的 AST 来说:
1 | <div v-if="ok"></div> |
没什么区别,都是一个元素带有不同属性而已,但是 vif 的操作是带有特殊语义的,不能像纯元素节点一样采用同样的代码生成方式,transform 的作用就在此,一方面解析 AST,一方面为生成代码做准备。因此这一部分也是 vue compiler 模块最复杂的部分。
codegen
即是 code generate。遍历 codegenNode,递归生成最终的渲染函数代码
Mini-Vue 的 compiler 实现原则
- 只实现能够支撑流程跑通的最基本的功能
- 舍弃所有的优化手段,选项功能
- 假定所有的输入都是合法的(不做任何的语法容错处理)
- 为了减少代码量,某些地方会使用一些与源码差别很大的简化手段
- 会舍弃一些非常麻烦的实现
认识 AST
1 | <div id="foo" v-if="ok">hello {{name}}</div> |

AST 分为元素节点,属性节点,指令节点,文本节点和差值节点
AST Node 的类型
其中 root 节点代表根节点,因为可能不止一个 root。SIMPLE_EXPRESSION 节点是简单表达式节点,附带在以上五种节点之中的节点,还有复杂表达式节点。
1 | const NodeTypes = { |
根节点
这里为了方便大大简化了。其实 vue 还有很多节点,用于优化的操作。所以这里只写了 children 方便我们执行。
1 | { |
纯文本节点
相当于例子中的 hello
1 | { |
表达式节点
这个 content 相当于例子中的 name,isStatic 表示它是否是静态。静态的话说明 content 就是一段字符串,动态的话 content 是一个变量 or 一段 js 表达式
1 | { |
插值节点
包含了表达式节点,content 相当于例子中的 name,isStatic 是 false 说明 name 是一个变量
1 | { |
元素节点
相当于例子中的 div,就是标签。当然因为也可以是自定义标签,比如组件类型,所以这里有个 tagType 标识是否是组件类型。然后属性节点和指令节点都在这里面
1 | { |
属性节点
相当于例子中的 id,但这个属性节点是可以没有 value 值的,比如 checked
1 | { |
指令节点
在下一节中有
指令节点
例子
1 | <div v-bind:class="myClass" /> |
这个例子可以解析成以下的情况:
name: bind, arg: class, exp: myClass
name: on, arg: click, exp: handleClick
它的代码是
1 | { |
其中 exp 就是解析的变量或者表达式,arg 就是函数名称或者绑定的变量名称,当然也可以不存在,比如 v-if 就没有
示例的最终结果
<div id="foo" v-if="ok">hello {{name}}</div>
我们接下来要将这个模板例子编译成以下的状态
1 | { |
ast
首先我们创建 compiler 目录新建 ast,index 和 parse 三个 js
下面是 ast 通过 createRoot 接收 children 然后返回一个根节点和它的孩子
1 | export const NodeTypes = { |
parse
vue 采用了设计模式编写这一部分的内容
首先是我们的 parse 函数,接收一个 content,通过 createRoot 函数返回编译后的结果
1 | export function parse(content) { |
createParserContext
通过这个返回接收到的模板字符串和提供编译的选项
1 | function createParserContext(content) { |
parseChildren
在实现 parseChildren 之前我们需要两个工具函数
advanceBy
我们的 vue 模板编译其实是像吃豆人一样的,需要一个一个字符串去消化,所以我们要根据情况截取字符串
1 | /** |
advanceSpaces
我们的 html 标签里面,其实也会有一些空格的情况出现,所以我们要去掉这些空格,否则会影响到我们的模板编译
1 | /** |
所以此时的 parseChildren 代码如下
1 | function parseChildren(context) { |
其中的循环条件函数为
isEnd
1 | function isEnd(context) { |
之后分为文本节点,元素节点,插值节点的处理
parseText
对于文本节点,我们可以用匹配的方式进行判断然后缩小范围。
比如<div id="foo" v-if="ok">hello {{name}}</div>
中,我们可以先匹配<,将范围缩小到hello {{name}}然后再匹配{缩小到hello最后利用 advanceBy 删除
1 | function parseText(context) { |
不过上面的方法还是有缺陷,比如识别不了a<b或者</这样的符号就不行,当然插值后面有文本也不行
parseTextData
1 | function parseTextData(context, length) { |
parseInterpolation
处理插值节点的思路就是找到前后的标识符,然后先去掉前面标识符的长度,再 parseTextData,最后再去掉后面标识符的长度。注意空格是合法的所以要对节点进行 trim
1 | function parseInterpolation(context) { |
parseElement
对于属性节点和指令节点我们放在 parseElement 里面去统一解析
<div id="foo" v-if="ok">hello {{name}}</div>
首先还是例子 对于这个例子来说,我们要解析出<div id="foo" v-if="ok">和</div>,那么前提就是要判断它的开始标签和结束标签,中间穿插这个解析
1 | start tag(解析属性,指令) |
对于标签,简单来说分为自闭合标签和非自闭合标签,所以我们单独写个函数分割
parseTag
这一部分中,通过正则将标签匹配出来,然后吃掉标签和空格,接着拿到属性和指令内容(这一步留到后面写)。
由于我们的标签还分为 组件标签 和 元素标签 所以我们再写函数进行判断
1 | function parseTag(context) { |
此时发现辨析标签比较困难,引入 vue 提供的解析标签到index.js
1 | const HTML_TAGS = |
并在配置项里增加
1 | function createParserContext(content) { |
此时我们的 isComponent 函数就可以编写了
1 | function isComponent(tag, context) { |
回到 parseElement,因为有了这个标签判断方法,大致的 js 如下
1 | function parseElement(context) { |
现在解决刚刚留下来的 parseAttributes,解析属性和指令节点
parseAttributes
parseTag 中已经帮我们截断了标签。所以目标是<div id="foo" v-if="ok">,不过我们依然需要判断是否自闭合,才进行解析。
1 | function parseAttributes(context) { |
这里的解析又需要用到parseAttribute方法
parseAttribute
这个方法是为了匹配并删除属性名产生的,匹配完之后,对于属性节点我们要获取等号后的内容,不过我们知道也不是时常有等号的,比如:checked就是没有等号也成立的内容,所以进一步封装方法 parseAttributeValue。对于指令节点,我们通过 match 后的 name 判断,因为指令节点一般以:,@,v-开头,分类判断,最后返回。不过我们在最后处理返回值的时候也要注意会有类似my-class的情况。要将他去掉-转为小驼峰才能识别myClass,需要个工具类函数帮助我们
1 | function parseAttribute(context) { |
parseAttributeValue
对于等号后的内容,其实不加引号和加引号都是合法的,这里偷个懒,认为输入的必须加引号才成立。方法就是获取第一个字符后匹配最后一个 index,再通过 parseTextData 获取内容, 最后删掉那个多余的引号
1 | function parseAttributeValue(context) { |
camelize
工具类中的转小驼峰的方法,例子是
1 | // my-first-class- |
代码
1 | export function camelize(str) { |
whitespace 优化
例子
1 | <!-- <div> |
这个例子中,如果我们采用原来的解析方法,会多了很多/r/n之类的不必要字符,算做了文本节点,所以这里有个优化的方法
1 | let removedWhitespaces = false; |
之后跑代码1
2import { parse } from "./compiler/index";
console.log(parse(`<div id="foo" v-if="ok">hello {{name}}</div>`))
如果结果如下 说明基本是正确的