前端工程化②打包体积优化
前言
本篇讲述 webpack 打包体积优化的思路和方向
如何分析打包体积
做过第三方依赖 CDN 引入的话,应该都了解到需要使用webpack-bundle-analyzer分析打包后的体积。
原理就是 webpack 打包后 Stats 数据进行分析。在 webpack compiler 的 done hook 进行处理。见源码;
1 | compiler.hooks.done.tapAsync("webpack-bundle-analyzer", (stats) => {}); |
stats数据:一个json文件,包含了模块的统计信息,用cli命令生成
在默认配置下,webpack-bundle-analyzer(opens new window)将会启动服务打开一个各个 chunk 下各个 module 占用体积的可视化图。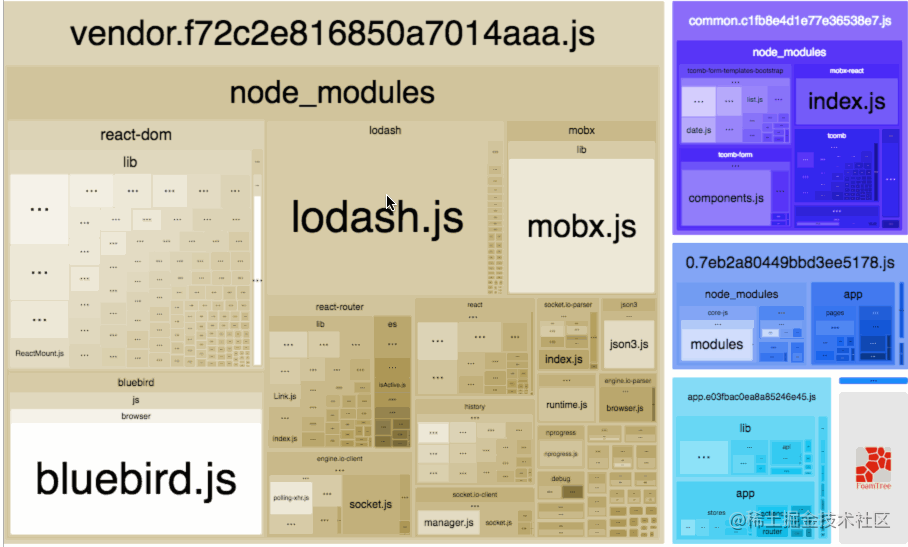
可以通过他找到在打包体积中最大的模块并进行优化。
在查看页面有三个选项:
- stat:每个模块的原始体积。
- parsed:每个模块经过 webpack 打包处理后的体积,比如 terser 等做了压缩,就会显示在上面。
- gzip:经过 gzip 压缩后的体积。
analyze
在实际项目中,往往通过环境变量 analyze 配置该插件,code 如下:
1 | const webpack = require("webpack"); |
在打包时,通过制定环境变量即可分析打包体积。
1 | ANALYZE=true npm run build |
js 压缩
通过 ast 分析,根据选项配置一些策略,来生成一颗颗粒更小体积的 AST 并生成代码
目前前端工程化中使用 terser 和 swc 进行 js 代码压缩,它们拥有相同的 api
常见的压缩 ast 的几种方案如下:
去除多余字符,空格,换行以及注释
code
1 | function sum(x, y) { |
此时这个文件大小是 62kb,一般来说中文会占用更多的空间。
多余的空白字符会占用大量的体积,如空格,换行符,另外注释也会占用文件体积。当我们把所有空白和注释都去掉之后,代码体积减小到 30kb,如下
1 | function sum(a, b) { |
不过替换掉多余的字符会有什么影响呢?
其实有影响的,比如代码压缩到一行的时候要注意行尾的分号。
压缩变量名,函数名,以及属性名
code
1 | function sum(first, second) { |
此时我们可以很明显的知道这两个变量只在 sum 的作用域产生影响,所以他们的变量名其实可以更短。
不仅如此,如果 sum 函数还是在一个 module 中不被导出,那么 sum 这个函数名也可以更短。
1 | // 压缩: 缩短变量名 |
在以上的示例中,当代码完成压缩的时候,其实代码的混淆也顺带完成。但此时缩短变量的命名需要在 ast 中支持,不至于在作用域中造成命名冲突。
解析程序逻辑,合并声明以及布尔值简化
合并声明的例子:
1 | const name = "jojo"; |
布尔值简化的例子
1 | !b && !c && !d && !e; |
解析程序逻辑:编译预运算
在编译期进行运算,减少运行时的计算量,如下示例:
1 | // 压缩前 |
以及一个更复杂的例子,简直是杀手锏级别的优化。
1 | // 压缩前 |
Tree Shaking
介绍:
Tree Shaking 指的是基于 ES Module 进行静态分析,通过 AST 将用不到的函数进行移除,从而减小打包体积。
例子:by rollup
1 | import { sum } from "./math.js"; |
mathjs
1 | export function sum(x, y) { |
打包后的代码
1 | // maths.js |
import *
当使用import *的时候,treeshaking 仍然有效.1
2
3
4
5
6import \* as maths from "./maths";
// Tree Shaking 依然生效
maths.sum(3, 4);
maths["sum"](3, 4);
import * as maths,其中 maths 的数据结构是固定的,无复杂数据,通过 AST 分析可查知其引用关系。1
2
3
4const maths = {
sum() {},
sub() {},
};
JSON TreeShaking
tree shaking甚至可以对json进行优化,原理是因为json格式简单,通过ast容易预测结果,不像js对象有复杂的类型与副作用。
1 | { |
1 | import obj from "./main.json"; |
引入支持 Tree Shaking 的 Package
在npm.devtool.tech中我们可以很清楚的看到每个包是否支持treeshaking。我们最好是引入支持treeshaking的包来减小生产环境的体积。
corejs polyfill
corejs是关于ES标准最出名的polyfill。polyfill指的是当浏览器不支持某个最新api的时候,他帮你实现,中文名称叫做垫片。
由于垫片的存在,打包后的体积便会增加,所支持的浏览器版本越高,需要的垫片越少,打包体积越小。
相应的如果要向下兼容,那么垫片就越多,打包体积就越大。
看一个Array.from的垫片代码,有了他的存在,任意浏览器都能使用这个api1
2
3
4// Production steps of ECMA-262, Edition 6, 22.1.2.1
if (!Array.from) {
Array.from = () => { // 省略若干代码 }
}
而Corejs的厉害之处就是他包含了所有的es6+的polyfill,并且集成在babel等编译工具之中。
曾经我们试过使用?.可选链操作符,babel会我们对应添加支持。但是如果是新的api就不是了,就需要corejs做polyfill帮助我们能够使用。目前他已经集成了,所以不用考虑这个问题。
browserslist
我们知道corejs能帮助我们给向下的浏览器兼容新的api,也知道了他的缺点是兼容的越多,需要的polyfill越多,体积越大。相应的就诞生了垫片体积控制工具browserslist
他用特定的语句来查询浏览器列表,如: last 2 Chrome versions
1 | $ npx browserslist "last 2 Chrome versions" |
细说起来,他是现代前端工程化必不可缺的一种工具。无论是处理js的babel,还是处理css的postcss,凡是与垫片有关的,它们背后都有browserslist的身影。
babel,在@babel/preset-env中使用core-js作为垫片postcss使用autoprefixer作为垫片
刚刚也说了垫片体积和浏览器版本直接挂钩,所以如果项目只需要支持最新的两个谷歌浏览器,那么关于browserslist的查询,可以写作last 2 Chrome versions
随着时间的推移,该查询语句会返回更新的浏览器,垫片的体积就会减小。
原理
browserslist的原理实际上就是根据正则解析查询语句。对浏览器版本数据库caniuse-lite进行查询,返回所得到的浏览器版本列表。
因为browserslist并不维护数据库,因此他会经常提醒你去更新caniuse-lite这个库,由于lock文件的存在,需要使用以下的命令去手动更新数据库。
1 | $ npx browserslist@last --update-db |
该命令将会对caniuse-lite进行升级,可以体现在lock文件中。
1 | "caniuse-lite": { |
一些常用的查询语法
如下:
根据用户份额
5%: 在全球用户份额大于 5% 的浏览器
5% in CN: 在中国用户份额大于 5% 的浏览器
根据最新浏览器版本
- last 2 versions: 所有浏览器的最新两个版本
- last 2 Chrome versions: Chrome 浏览器的最新两个版本
不再维护的浏览器
- dead: 官方不在维护已过两年,比如 IE10
浏览器版本号
- Chrome > 90: Chrome 大于 90 版本号的浏览器
总结